
Specialized Storage Paradigms
In addition to widely known SQL and NoSQL databases, such as document or key-value stores, there are specialized storage paradigms that are well-suited for specific use cases. We will discuss four of them below:
Blob Storage
Blob storage is a common storage solution used in both small and large-scale systems. While not considered a database per se, it allows users to store and retrieve data based on a blob’s name. This is similar to a key-value store, but with different performance guarantees. Blob storage may be slower than key-value stores, but it can handle much larger values, such as megabytes or even gigabytes.
Common use cases for blob storage include storing large binaries, database snapshots, or static assets like images for websites. Blob storage infrastructure is complex to maintain on-premises and is typically provided by large companies like Google, Amazon, or Microsoft. In the context of system design interviews, you can assume the availability of GCS, S3, or ABS, which are blob storage services hosted by Google, Amazon, and Microsoft, respectively.
Time Series Database
A Time Series Database (TSDB) is a specialized database optimized for storing and analyzing time-indexed data—data points occurring at specific moments in time. Examples of TSDBs include InfluxDB, Prometheus, and Graphite, which are primarily used for monitoring purposes.
Graph Database
Graph databases store data using a graph data model, allowing data entries to have explicitly defined relationships, similar to nodes and edges in a graph. They leverage their graph structure to perform complex queries on deeply connected data efficiently.
Graph databases are often preferred over relational databases when dealing with systems where data points naturally form a graph with multiple levels of relationships, such as social networks.
Cypher
Cypher is a graph query language originally developed for the Neo4j graph database but has since been standardized for use with other graph databases, aiming to become the “SQL for graphs.” Cypher queries are generally simpler than their SQL counterparts. For example, a Cypher query to find data in Neo4j, a popular graph database:
MATCH (some_node:SomeLabel)-[:SOME_RELATIONSHIP]->(some_other_node:SomeLabel {some_property:'value'})
Spatial Database
Spatial databases are designed for storing and querying spatial data, such as map locations. They utilize spatial indexes like quadtrees to perform spatial queries efficiently, like finding all locations near a specific region.
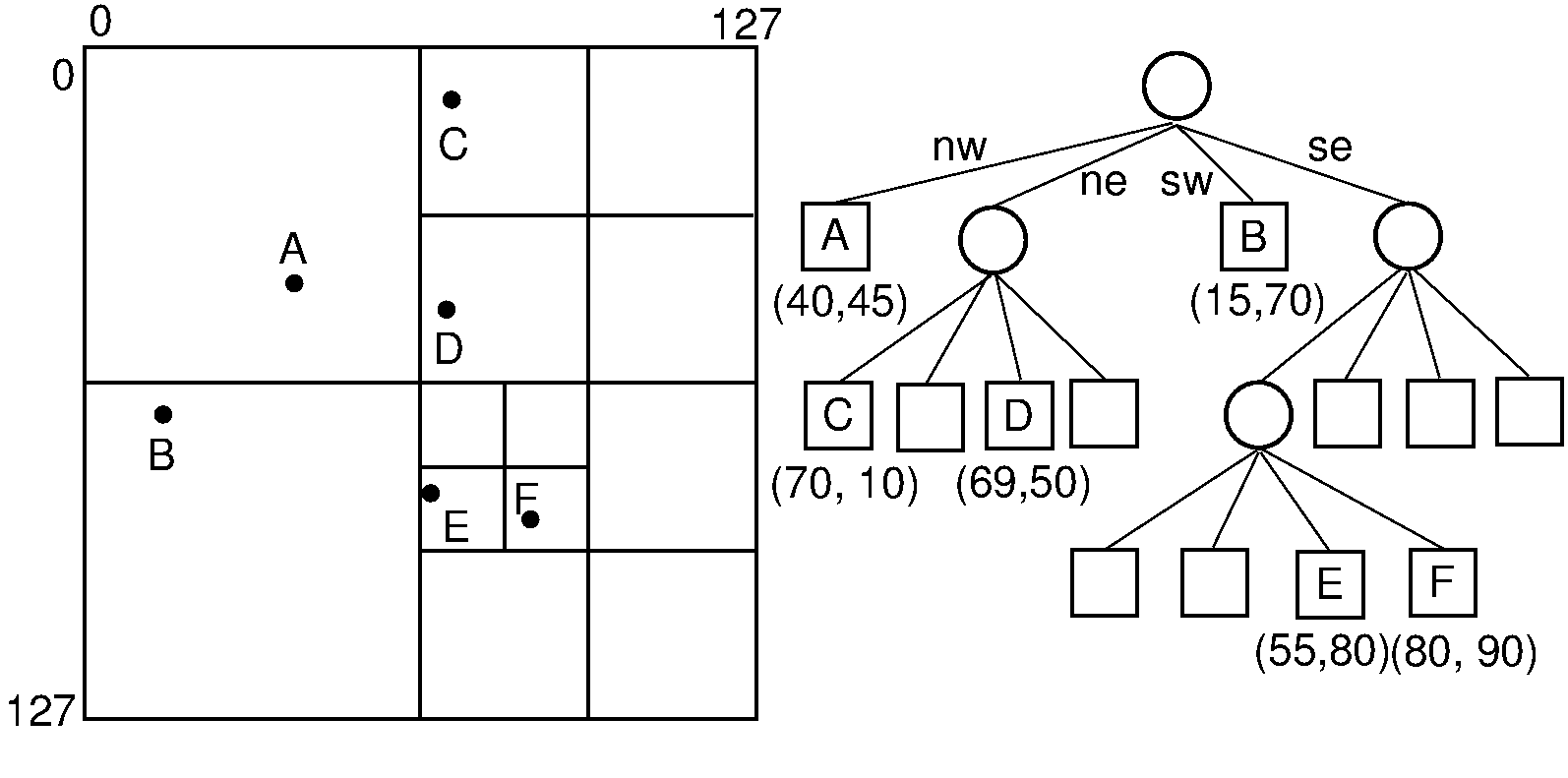
Quadtree
A quadtree is a tree data structure commonly used to index two-dimensional spatial data. Each node in a quadtree has either zero child nodes (leaf nodes) or exactly four child nodes. Quadtree nodes typically contain spatial data, such as map locations, with a maximum capacity of a specified number n.
As long as nodes are not at capacity, they remain leaf nodes; when they reach capacity, they are given four child nodes, and their data entries are distributed among the children. Quadtrees are well-suited for storing spatial data, as they can be represented as a grid filled with rectangles that are recursively subdivided into four sub-rectangles. Each quadtree node corresponds to a rectangle, and each rectangle represents a spatial region.
Comments