
Hashing
Hashing is a process that transforms an arbitrary piece of data into a fixed-size value, typically an integer. In the context of system design, this arbitrary data could be an IP address, username, HTTP request, or anything that can be hashed or transformed into an integer value. Hashing plays an essential role in various aspects of system design.
Let’s look at an example, how hashing can be used in load balancers. Imagine that we have four clients, four servers (each with its own cache), and a load balancer that distributes the load. The requests that clients issue are computationally expensive, meaning they involve significant resources and time to complete.
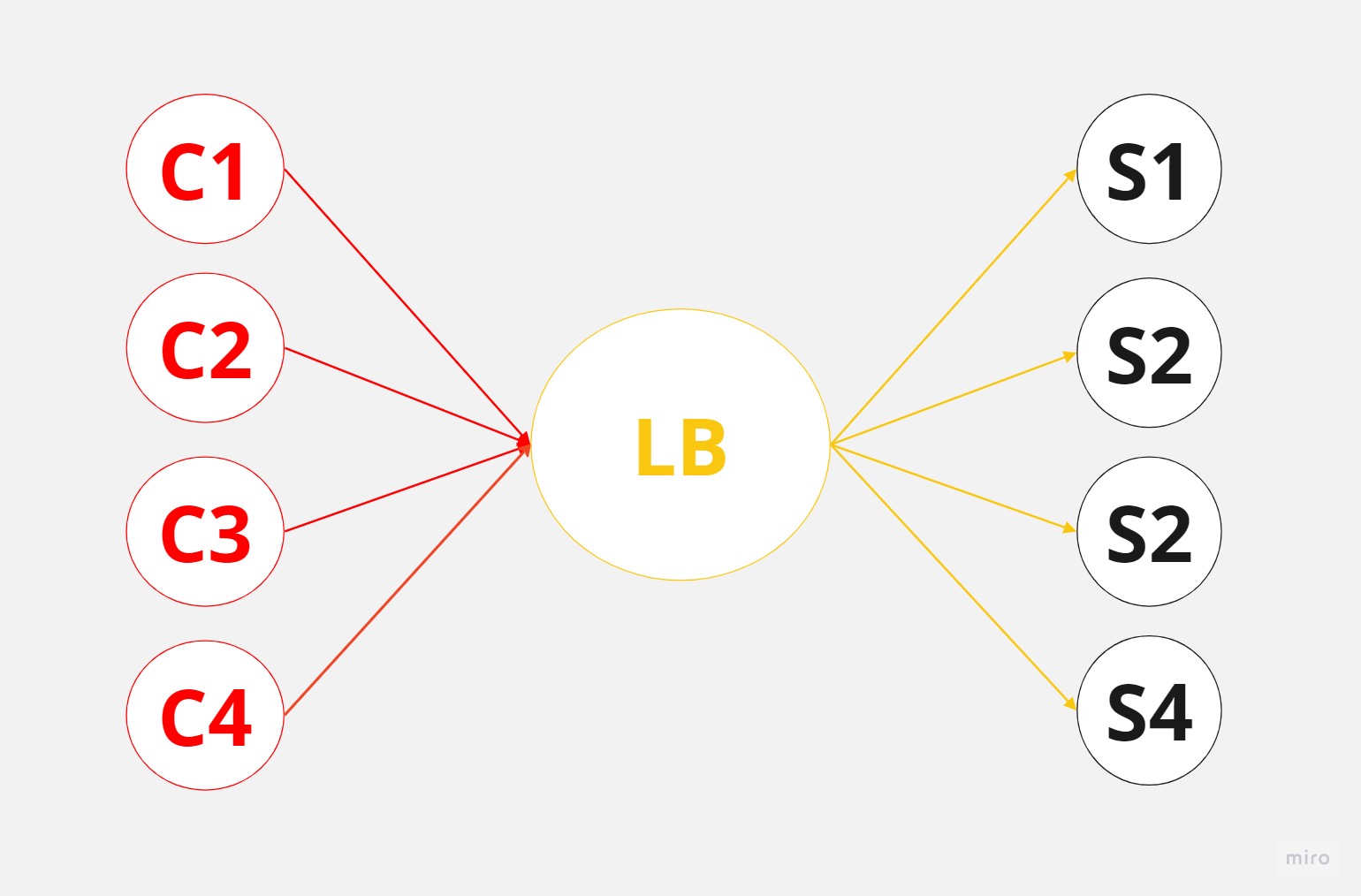
Without the right selection strategy, the load balancer may direct requests to a server that doesn’t have the necessary cached data. This is where hashing comes into play.
By hashing the incoming requests, we can assign them to specific servers based on the hash value. In this example, we’ll hash the client names (C1, C2, C3, C4) to distribute the requests evenly across the servers.
Let’s assume we have a hashing function that returns the following results:
C1 -> 11
C2 -> 12
C3 -> 13
C4 -> 14
Now we can use the modulo operation to map these hashes to the servers (in this case, four servers):
11 % 4 = 3
12 % 4 = 0
13 % 4 = 1
14 % 4 = 2
This means that C1 should be associated with server D, C2 with server A, C3 with server B, and C4 with server C.
Importance of a good hashing function
A good hashing function should provide uniformity, ensuring that clients are evenly distributed among the servers. This doesn’t mean that two clients won’t map to the same server, but it does mean that a well-designed hashing function should distribute data values evenly.
In practice, you should use a pre-made, industry-grade hashing algorithm like MD5, SHA-1, or BCrypt, which ensures uniformity.
By using hashing, we maximize the chance of getting cache hits, as all requests from a particular client will always be directed to the same server.
Handling changes in server count
However, in distributed systems, issues like server failures or the need to add new servers can arise. If a server dies or if we need to add a new server, we must adjust our hashing strategy accordingly.
For example, if we add a fifth server (E), we can no longer mod by four; we must mod by five:
11 % 4 5 -> 3 1
12 % 4 5 -> 0 2
13 % 4 5 -> 1 3
14 % 4 5 -> 2 4
Now, C1 will be directed to server B instead of server D, C2 to server C instead of server A, and so on. This change means that we will once again face the problem of missing cache hits, as the new server assignments do not have the previously cached data.
In summary, hashing is a crucial technique in system design, helping to distribute requests evenly across servers and maximize cache hits. However, it’s essential to adjust the hashing strategy when adding or removing servers to ensure continued optimal performance.
How to Solve the Problem of Adding or Removing Servers?
Consistent hashing and rendezvous hashing are two slightly more complex hashing strategies that address the issue of adding or removing servers. Both strategies minimize the number of keys that need to be remapped when a hash table gets resized, which is especially useful for load balancers that distribute traffic to servers but not only.
Consistent Hashing
Consistent hashing is a technique that minimizes the number of requests that get forwarded to different servers when new servers are added or existing ones are removed. To better understand how it works, let’s consider an example.
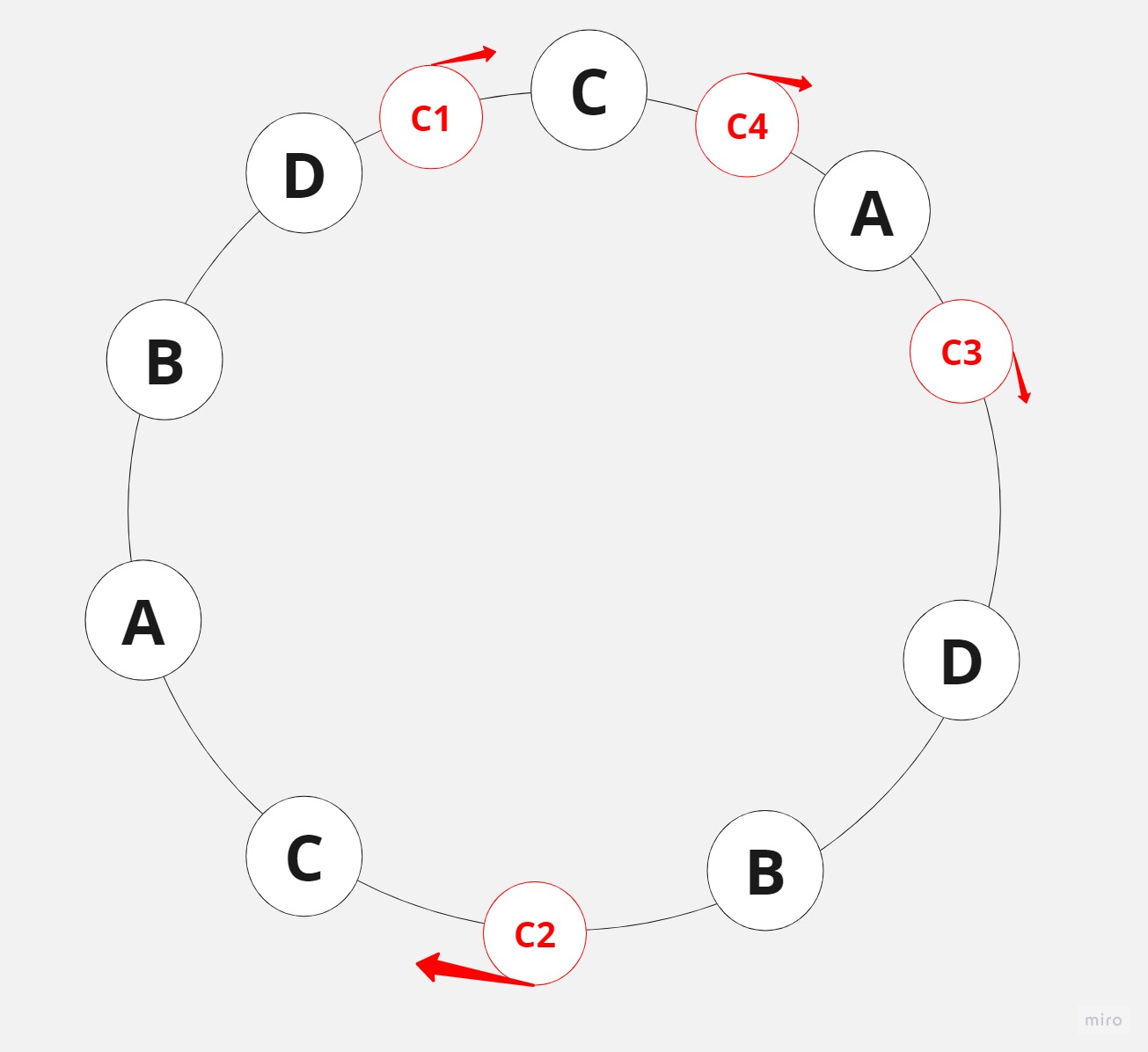
Imagine servers being organized on a circle, which is not a physical object but rather a conceptual representation to help us visualize the consistent hashing strategy. The servers are more or less evenly distributed along the circle, and their placement is determined by the output of a hashing function applied to each server’s name or identifier.
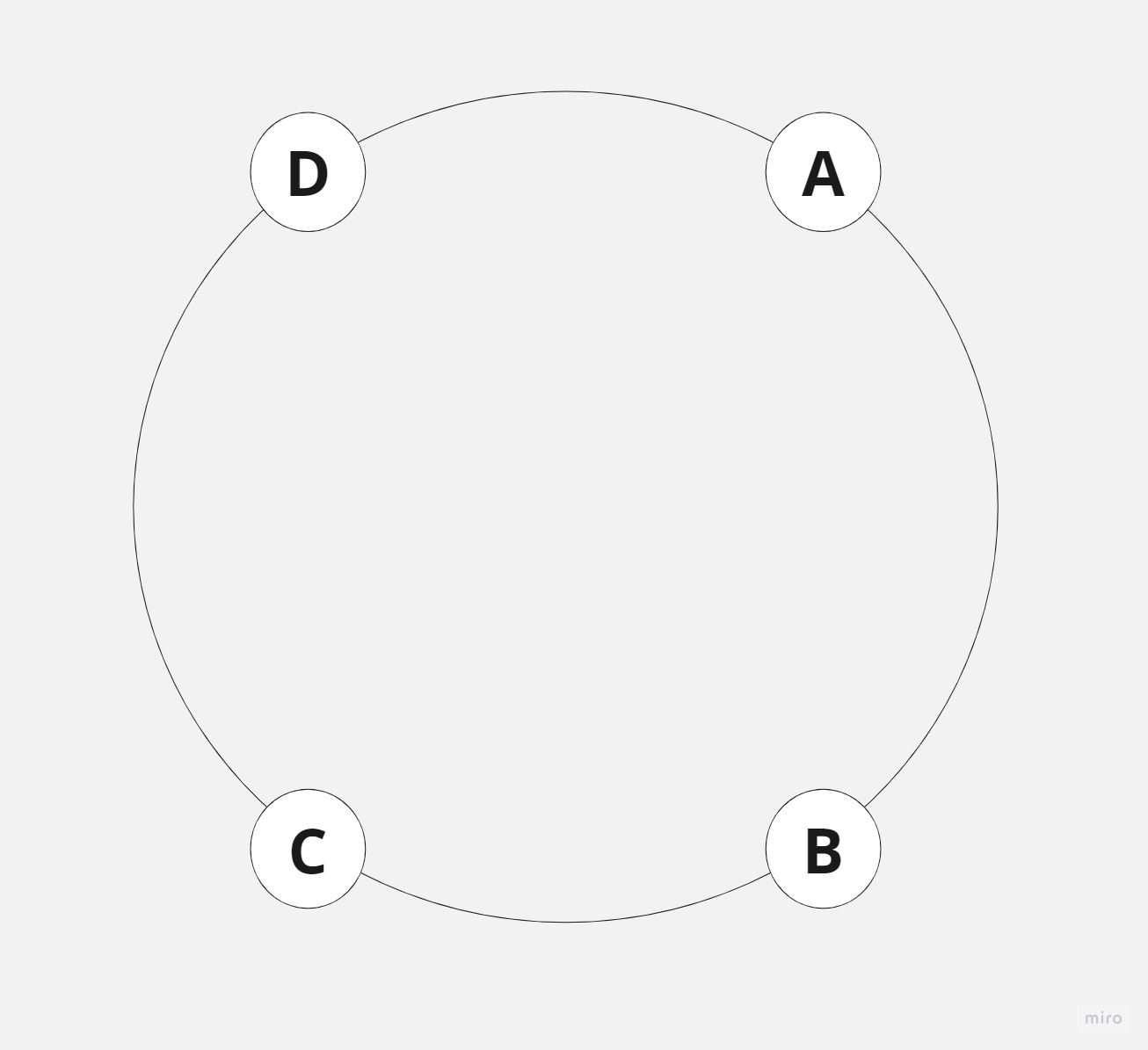
Clients are also placed on the circle using a hashing function, which might take the client’s IP address, username, or some other identifier as input.
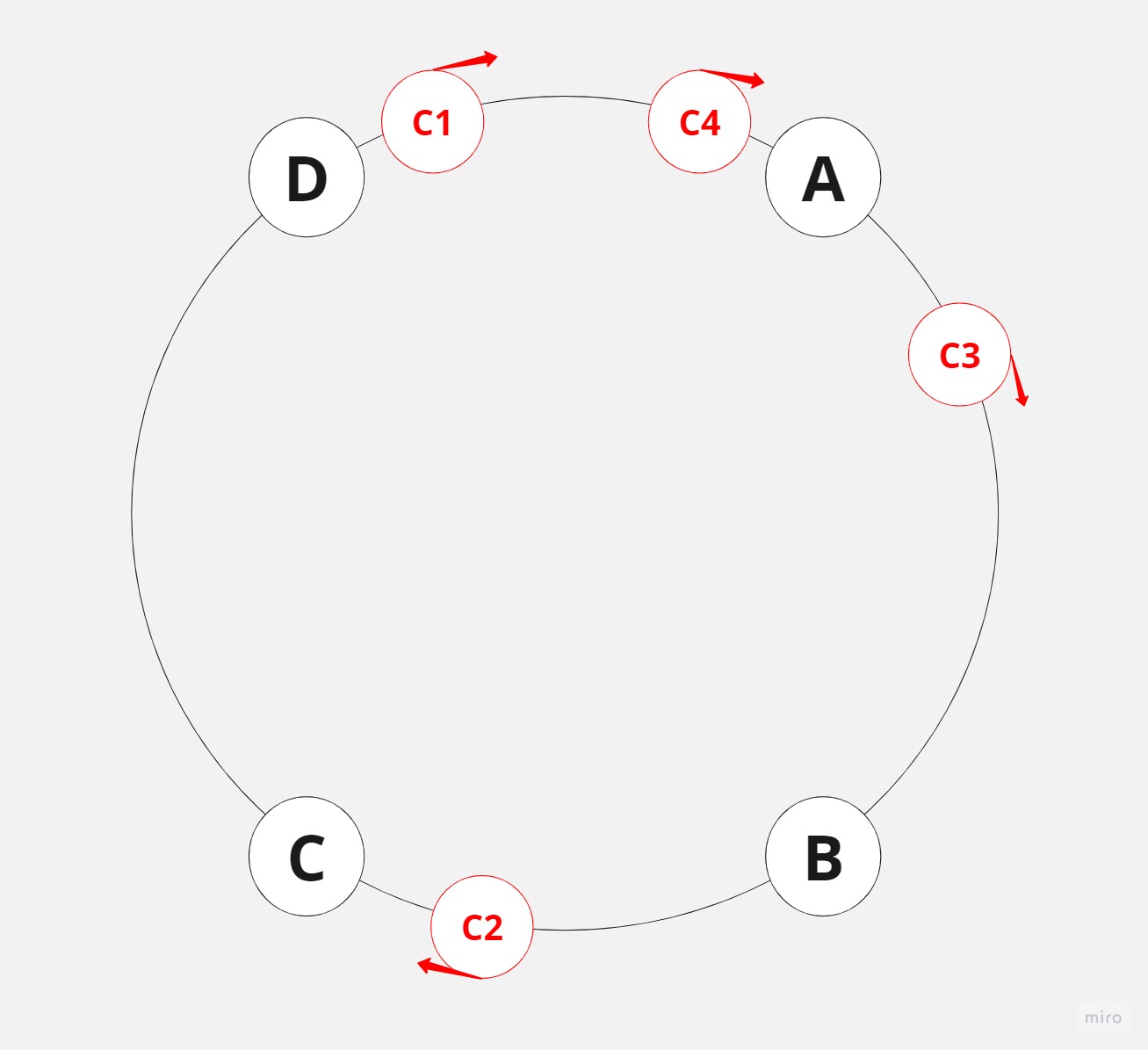
To determine which server a request should be routed to, you start from the client’s position on the circle and move clockwise (or counterclockwise) until you encounter a server. That server is where the load balancer will redirect the client’s request.
Consistent Hashing Advantages
Consistent hashing is advantageous because it maintains most of the previous mappings between clients and servers even when servers are added or removed.
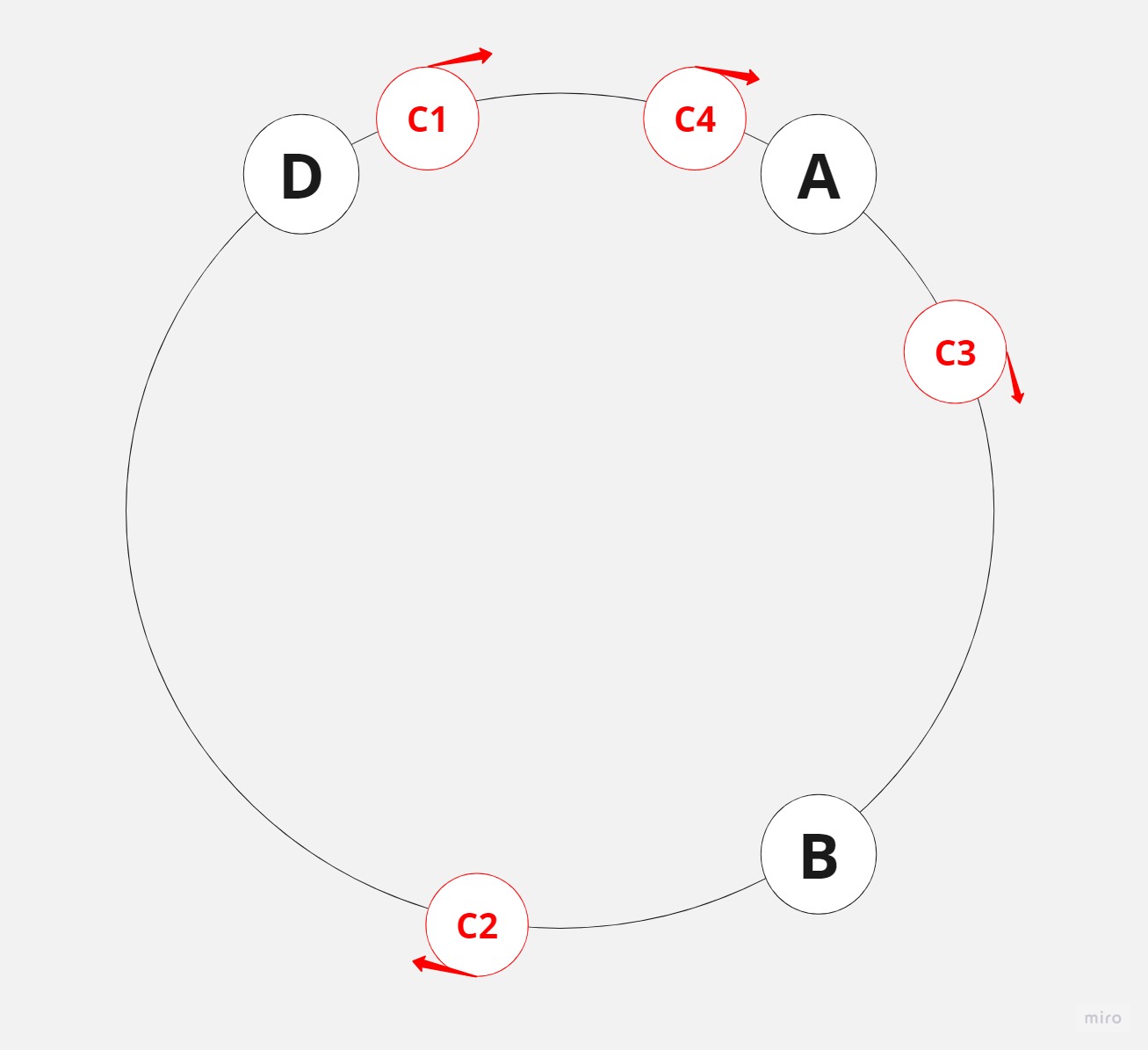
In the previous example with a simple hashing strategy, if a server went down, all calculations would need to be redone. For instance, if there were four servers and one died, the modulus operation would no longer be done by four, but rather by three.
However, with consistent hashing, if a server goes down – let’s say server C – the clients will move in a clockwise direction to find the closest server. For most clients, nothing changes, but since server C is down, C2 will be redirected to server D.
In cases where you want to distribute the load more evenly across servers, you can pass the servers or server through multiple hashing functions and place the resulting hashes on the circle. This approach allows you to distribute the load more evenly or assign more responsibility to more powerful servers and distribute traffic more fairly.
Consistent hashing is powerful because it maintains a level of consistency between hashes and their target buckets, ensuring a more stable relationship between clients, or requests, or IP addresses, and servers or whatever else you’re using.
Rendezvous Hashing
Rendezvous Hashing, or Highest Random Weight Hashing, works by assigning each server a weight based on a combination of the server’s identifier and the data item’s key. The server with the highest weight for a given key is chosen to store the corresponding data item. This ensures an even distribution of data items across the available servers, while also providing fault tolerance and minimizing data movement when servers are added or removed.
Here’s an example to illustrate how Rendezvous Hashing works:
Suppose we have four servers (A, B, C, and D) and three ip addresses (IP1, IP2, IP3). To determine which server will handle each IP addresses, we’ll calculate the weight for each server-IP address combination using a consistent hashing function.
IP1:
Server A: weight 3.0
Server B: weight 1.5
Server C: weight 2.1
Server D: weight 1.9
In this case, server A has the highest weight for IP address IP1, so it will be responsible for handling IP1.
IP2:
Server A: weight 1.1
Server B: weight 2.7
Server C: weight 0.5
Server D: weight 1.8
Server B has the highest weight for IP address IP2, so it will be responsible for handling IP2.
IP3:
Server A: weight 2.2
Server B: weight 1.9
Server C: weight 3.5
Server D: weight 0.7
Server C has the highest weight for IP address IP3, so it will be responsible for handling IP3.
Now let’s say server C goes down. To redistribute the IP addresses, we only need to recalculate the weights for server C IP addresses (in this case, IP3).
IP3:
Server A: weight 2.2
Server B: weight 1.9
Server D: weight 0.7
Server A now has the highest weight for IP address IP3, so it will be responsible for handling IP3.
The other IP addresses remain assigned to their original servers, minimizing the amount of redistribution required.
In conclusion, Rendezvous Hashing is an effective technique for distributing IP addresses across multiple servers, ensuring even load balancing and fault tolerance. Its ability to minimize redistribution when servers are added or removed makes it particularly well-suited for dynamic, large-scale distributed systems.
Comments