
Load Balancing
A load balancer can be better understood through a simple use case. Consider a basic client-server architecture where a client sends requests to a server, which processes them and returns a response. Now, imagine the system expanding with multiple clients (two, three, four, and so on) sending requests to a single server. Clients might issue multiple requests as well.
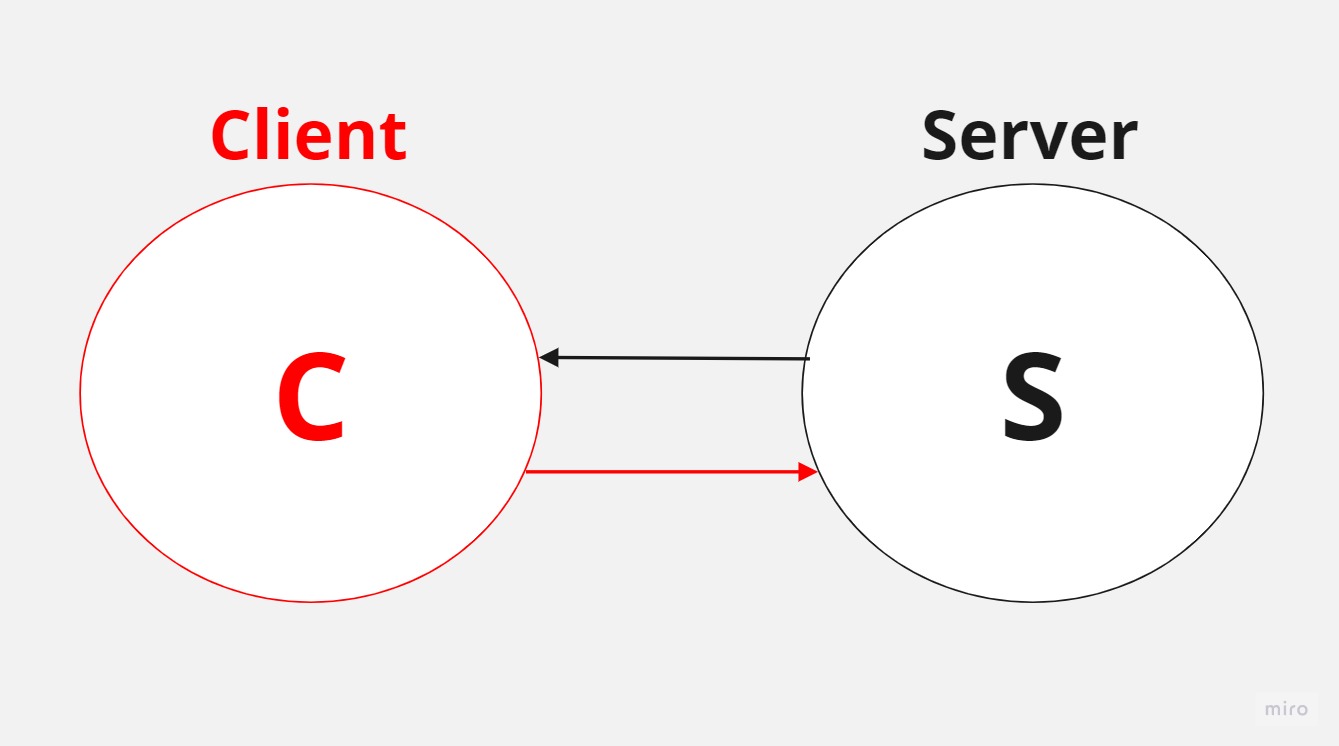
The single server has limited resources and can only handle a certain number of requests within a given time, thus limiting the system’s throughput. The more requests the server receives from various clients, the more likely it is to become overloaded, potentially leading to system failure or slow performance.
To address this issue, the system needs to be scaled. There are two ways to accomplish this:
-
Vertical scaling involves increasing the server’s power and performance. However, there is a limit to how much a single server or machine can be enhanced.
-
Horizontal scaling means adding more servers or machines to the system. For example, if we have four servers, the system can now handle requests from clients in a balanced way. Assuming that all servers have equal resources and power, the system can handle four times the load it could previously manage with only one server. This assumes that all clients distribute their requests evenly among the servers.
The challenge is determining how clients know which server to send their requests to. This is where load balancers come into play.
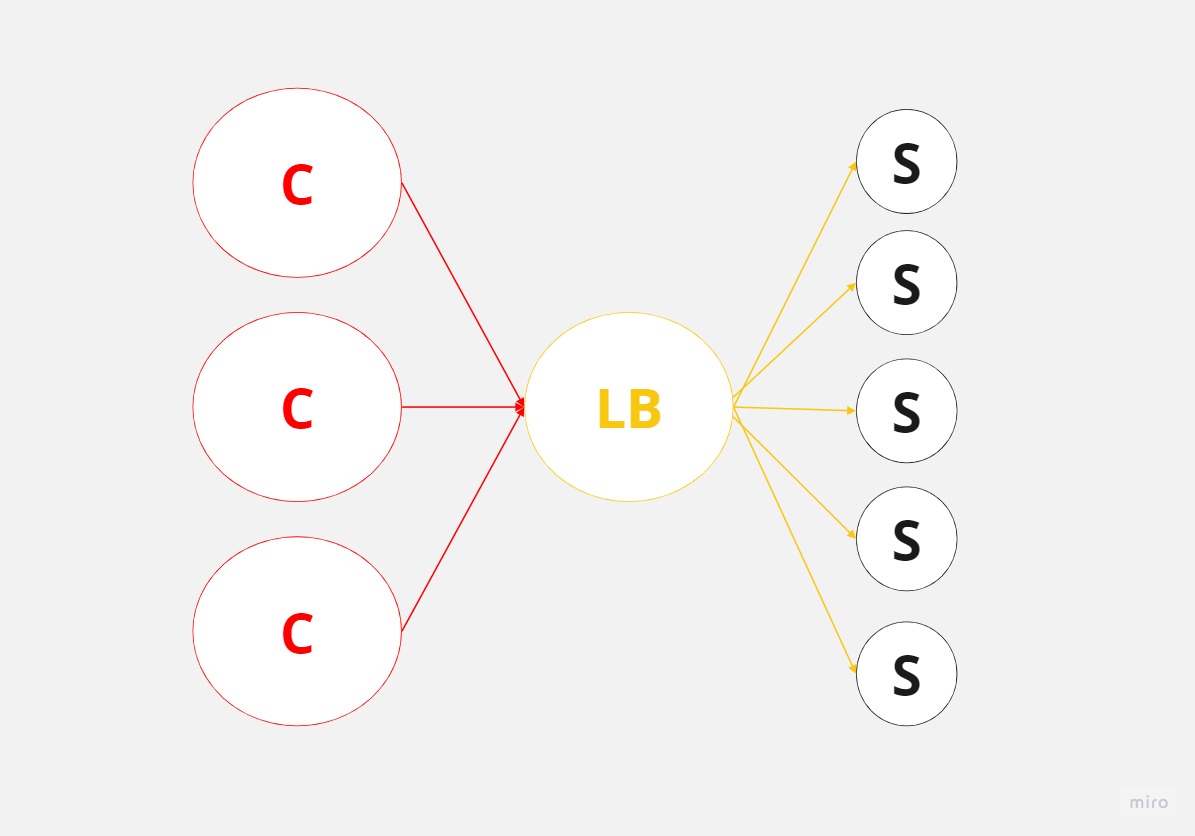
A load balancer is a server that sits between a group of clients and a set of servers (at least in our example), with the primary responsibility of distributing workloads across resources. In this case, it balances or reroutes traffic from clients to servers in a balanced or preconfigured manner.
In a system with a load balancer, clients issue requests that are directed to the load balancer. The load balancer’s job is to redirect these requests to the servers in a balanced manner. This results in traffic being evenly distributed across all the servers, allowing for effective horizontal scaling.
Load balancers are highly beneficial as they prevent resources, such as single or multiple servers, from becoming overloaded. They also enhance the overall system throughput, as the servers can respond to requests faster without being bogged down. Consequently, this leads to better latencies and more efficient use of resources. As new servers are added to the system, the load balancer distributes traffic to these new resources, ensuring optimal performance.
Often, load balancers can be considered a type of reverse proxy, as they sit between clients and servers and typically act on behalf of the servers.
Load balancing can occur at various points within a system. For example, a load balancer might be placed between clients and servers, between servers and databases, or even at the DNS layer when dealing with websites.
Server-Selection Strategy
How a load balancer chooses servers when distributing traffic amongst multiple servers?
Firstly it’s essential to recognize that there are different types of load balancers, such as software load balancers and hardware load balancers.
Hardware load balancers are physical machines dedicated to load balancing. In contrast, software load balancers offer more customization and scaling options. Hardware load balancers are limited by their given hardware, which can be expensive. For this discussion, we will focus on software load balancers and the techniques they use to distribute traffic to servers.
Software load balancers use various algorithms to distribute incoming client requests across multiple servers. Some common load balancing methods include:
-
Pure Random: Another method is using pure random redirection, in which the load balancer directs traffic to the servers in a purely random order. While this approach may work in some cases, it could potentially cause problems. For instance, one server might become overloaded by chance, leading to uneven load distribution and possible performance issues. Nonetheless, the pure random method can still be an option for load balancing, depending on the specific requirements and system architecture.
-
Round Robin: In this method, requests are distributed sequentially and cyclically among the available servers. The load balancer starts with the first server, moves through the list to the last server, and then goes back to the first server, continuing this pattern for subsequent requests. Round Robin works well when servers have similar capacities.
-
Weighted Round Robin: An extension of the Round Robin method is the Weighted Round Robin, where each server is assigned a weight based on its capacity or performance. The load balancer distributes requests according to these weights while still following the sequential and cyclical order. Servers with higher weights receive more requests, ensuring that the distribution takes into account the varying capabilities of the servers. This method offers a more balanced approach when server capacities differ significantly.
-
Performance-Based: In a performance-based approach, the load balancer continuously monitors the performance of the available servers and distributes incoming requests based on each server’s current performance metrics. The load balancer may consider factors such as CPU usage, memory usage, network latency, or how much traffic a server is handling at any given time when making its decision.
-
IP Hash: The client’s IP address is used to determine which server will handle the request. This method ensures that a specific client will always connect to the same server, as long as the server is available. The IP hash technique may be very useful when the server caches the results of requests, as the same clients will connect to the same servers the cache hits will be maximized, leading to improved performance and reduced latency.
-
Path-Based: The URL path or specific segments of a request’s path are used to determine which server will handle the request. This method allows for efficient distribution of traffic among multiple servers based on the type of content or service being requested.
These and more techniques help ensure that incoming requests are evenly distributed among the available servers, reducing the likelihood of overloading any single server and maintaining optimal system performance.
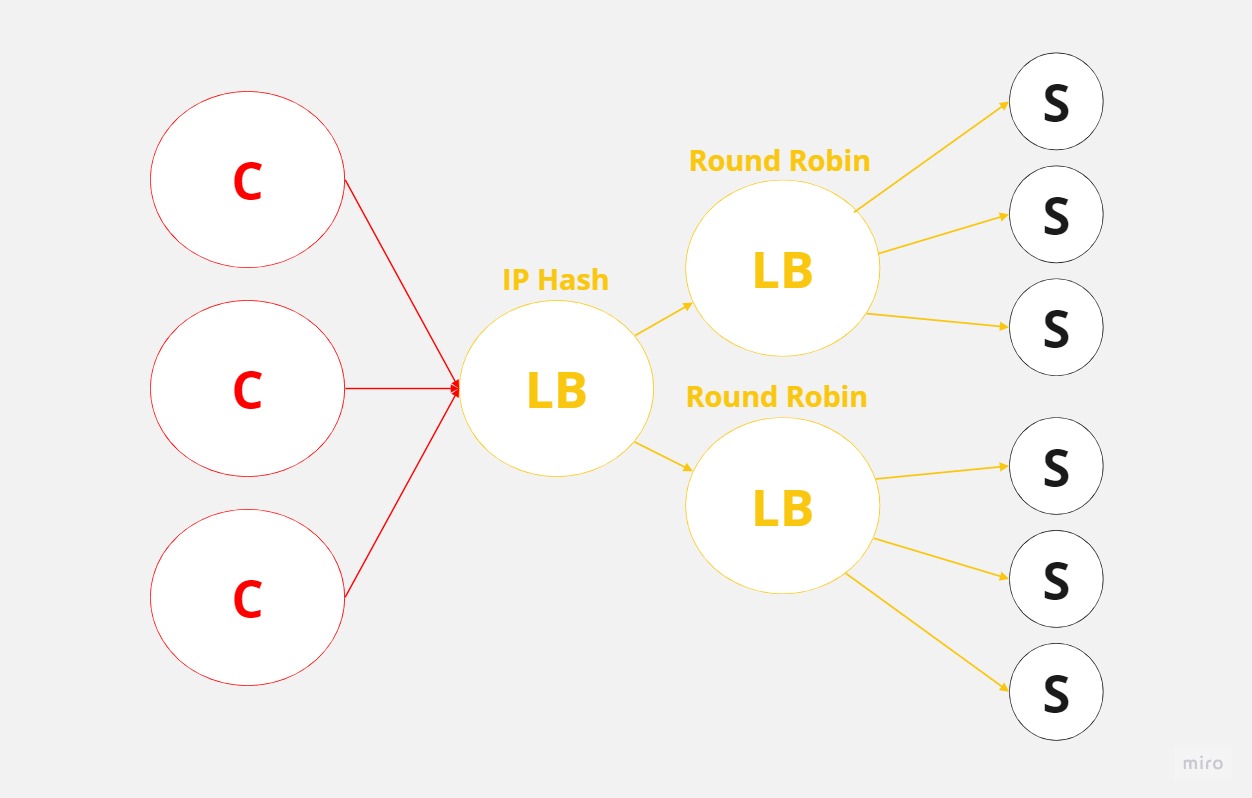
When you’re going to be designing systems, you’re going to want to pick server selection strategies according to your use case. Interesting thing about all of this is that when you’re designing a system, it might actually make sense to have multiple load balancers that use different server selection strategies.
For example, clients may hit a load balancer, which will distribute the load using IP hash selection strategy to the next load balancers which might use Round Robin strategy.
Hot Spot
When distributing a workload across a set of servers, the workload might be allocated unevenly. This imbalance can occur if your sharding key or hashing function is suboptimal, or if the workload is inherently skewed. As a result, some servers may experience significantly higher traffic than others, leading to the creation of “hot spots.”
Comments